
Recently, Ashok Elluswamy, director of Tesla's self-driving software, gave a speech at the CVPR 2022 conference. In his speech, he stated many of the achievements of Tesla's Autopilot system team in the past year. He made mention of the neural network model called Occupancy Networks. He mentioned that there are many problems with semantic segmentation and depth information traditionally used in autonomous driving systems. For example, it is difficult to convert 2D to 3D, and the estimation of depth information is inaccurate. After using the occupancy network, the model is able to predict the space occupied by objects around the vehicle.

Based on this, the vehicle can make an evasive action without needing to recognize what the specific obstacle is. Ashok Elluswamy even joked on Twitter that Tesla's car can even avoid UFOs. Based on this technology, the vehicle can also see if there are obstacles in the surrounding corners so that it can achieve unprotected steering like a human driver. In short, occupying the network significantly enhances Tesla's self-driving capabilities (L2). According to Tesla, its Autopilot system prevents 40 crashes a day due to driver error.
By sensing the external environment and the driver's operating system, the vehicle can recognize the driver's misoperation. A driver could step on the accelerator pedal at the wrong time, the vehicle will stop accelerating and brake automatically. That is to say, some of the "brake failure" problems that have been frequently exposed in China due to driver's misoperation will be technically restricted. Tesla is really good at driving technological progress. Here are the highlights of Ashok Elluswamy's speech.
Powerful pure vision algorithm - 2D image to 3D
According to Ashok, the Tesla Autopilot system can help the vehicle achieve lane keeping, vehicle following, deceleration and cornering, etc. In addition to these, the Tesla Autopilot system also supports standard safety features. It supports emergency braking and obstacle avoidance, which can prevent multiple collisions. In addition, since 2019, about 1 million Teslas can use more advanced navigation on highways, check adjacent lane information to perform lane changes, and identify highway entrances and exits. Tesla’s Autopilot system can also automatically park in parking lots, recognize traffic lights and street signs, and make right turns to avoid obstacles such as cars. At present, these features have been verified by hundreds of thousands of Tesla owners.

The system recognizes the surrounding environment
According to Ashok, Tesla uses eight 1.2-megapixel cameras, which can capture 360-degree images of the surrounding environment, generating an average of 36 frames per second. Tesla’s car will then process this information, performing 144 trillion operations per second (TeraOPs/s). These processes are all based on pure visual algorithms, without using lidar and ultrasonic radar, and without high-definition maps.
How does the Tesla Autopilot system recognize general obstacles?
Ashok claims the system uses a spatial segmentation method when encountering general obstacles. When using the space segmentation method, the system labels each pixel in the space as "drivable" and "non-drivable", and the autonomous driving chip then processes the scene. However, there are some problems with this method.

Marking of objects
First of all, the object pixels marked by the system are in two-dimensional space, and in order to navigate the car in three-dimensional space, the object pixels need to be converted into corresponding predicted values in three-dimensional space. Thus, Tesla's system can establish an interactive physical model and smoothly handle navigation tasks.

Marking of objects
When the system converts object pixels from a two-dimensional image to a three-dimensional image, it needs to perform image semantic segmentation. This process produces unnecessary images or unnecessary pixels in the system. A few pixels on the ground plane of an image can have a huge impact on directly determining how this 2D image is transformed into a 3D image. Therefore, Tesla does not want to have such a large pixel in the planning.
Different obstacles also need to be judged using different methods
Generally speaking, the depth value of the object is more commonly used. In some scenarios, the system can predict obstacles first. In another scenario, the system can also detect depth on the pixels of the image, so each pixel produces some depth value.

Depth map (right side)
However, while the resulting depth map is very beautiful, when making predictions with the depth map, only three points are needed. And when visualizing these three points, although it looks fine up close, they also deform as the distance increases, and these images are difficult to continue to use in the next stage. For example, walls may deform and become curved. Objects near the ground plane are also determined by fewer points, which makes the system unable to correctly judge obstacles during planning. Because these depth maps are converted from plane images captured by multiple cameras, it is difficult to generate an identical obstacle in the end. Furthermore, it is also difficult for the system to predict the boundary of the obstacle. Therefore, Tesla came up with the Occupancy Network solution to solve this problem.
Calculate the space occupancy rate to encode the object
Ashok demonstrates the occupancy network and reveals that the system processes the images from 8 cameras and then calculates the space occupancy rate of the object. With this, it finally generates a schematic diagram.

Generated simulated image
And every time the Tesla car moves while driving, the system network will recalculate the space occupancy of surrounding objects. In addition, the system network will not only calculate the space occupancy rate of some static objects, such as trees and walls but also calculate the space occupancy rate of dynamic objects, including moving cars. After that, the network outputs the image as a 3D image, and can also predict occluded objects. Thus, even if the car uploads only a partial outline of the object, the user can distinguish the object clearly.
Obstacle type is not important - the system can avoid the crash
Ashok also claims that regular motion or mobile networks cannot tell the type of objects, such as whether it is a static object or a moving vehicle. But from the control level, the type of object does not actually matter. The occupying network scheme provides good protection against the classification dilemma of the network. Because no matter what the obstacle is, the system will think that this part of the space is occupied and move at a certain speed. Some special types of vehicles may have strange protrusions that are difficult to model with traditional techniques. The system uses cubes or other polygons to represent moving objects.
In this way, objects can be arbitrarily extruded, using this placeholder approach, without the need for complex mesh-like topology modelling. Geometric information can be used to infer occlusion when the vehicle is making unprotected or protected turns. Geometric information requires not only inferring information recognized by vehicle cameras but also inferring information not recognized.
Ashok claims that when Tesla's vehicle is running, the background processing of the images it gets is more accurate. Thus, it can generate a cross-time and accurate image route (using NeRf). With this, it generates more accurate images through the NeRf model and 3D state differential rendering.
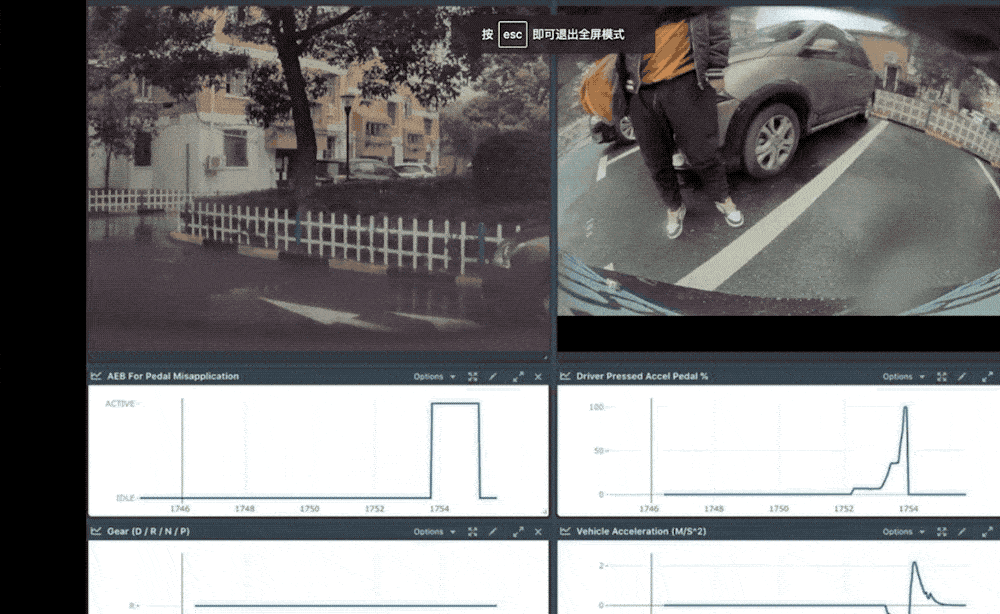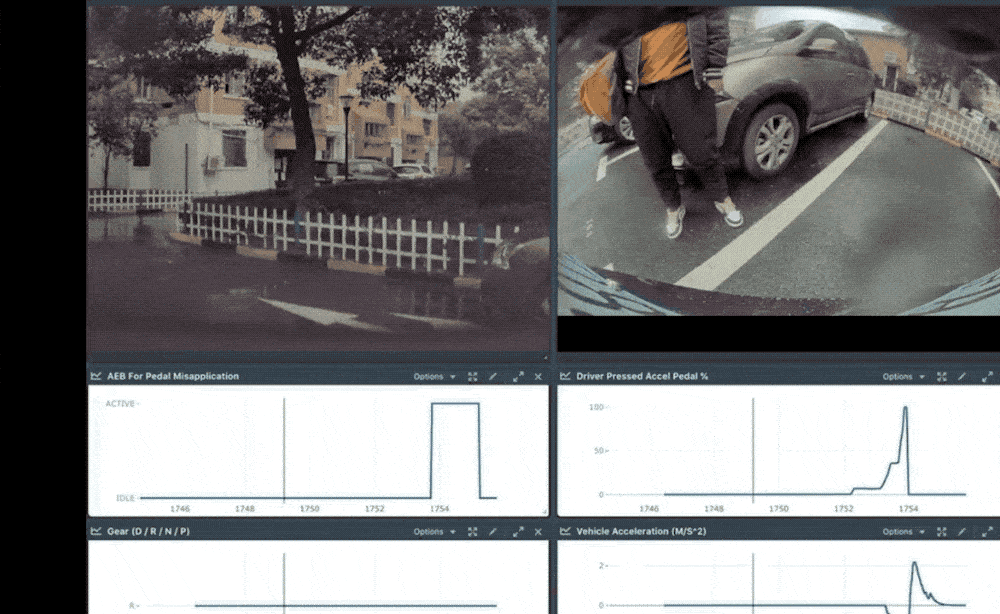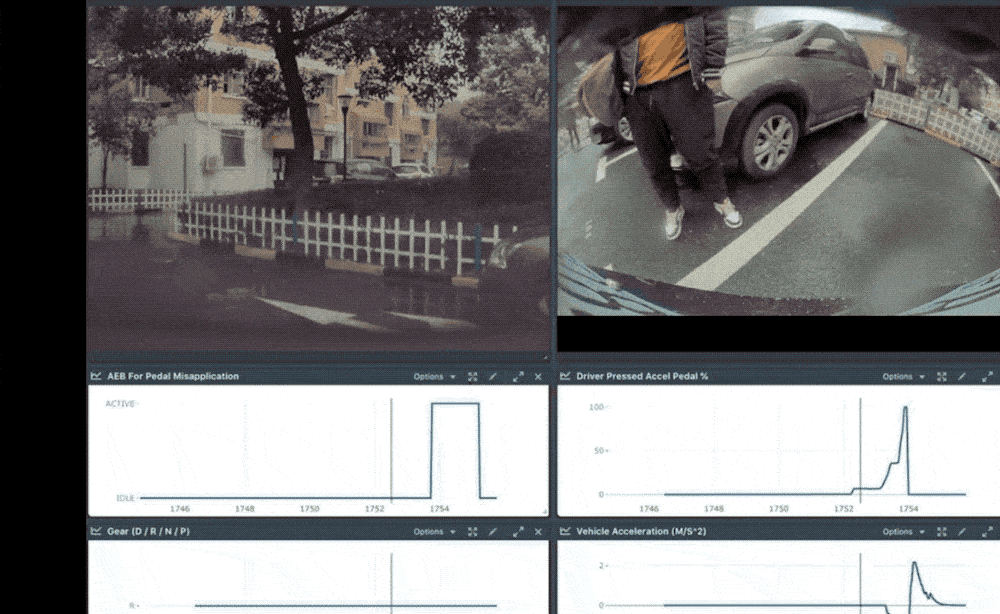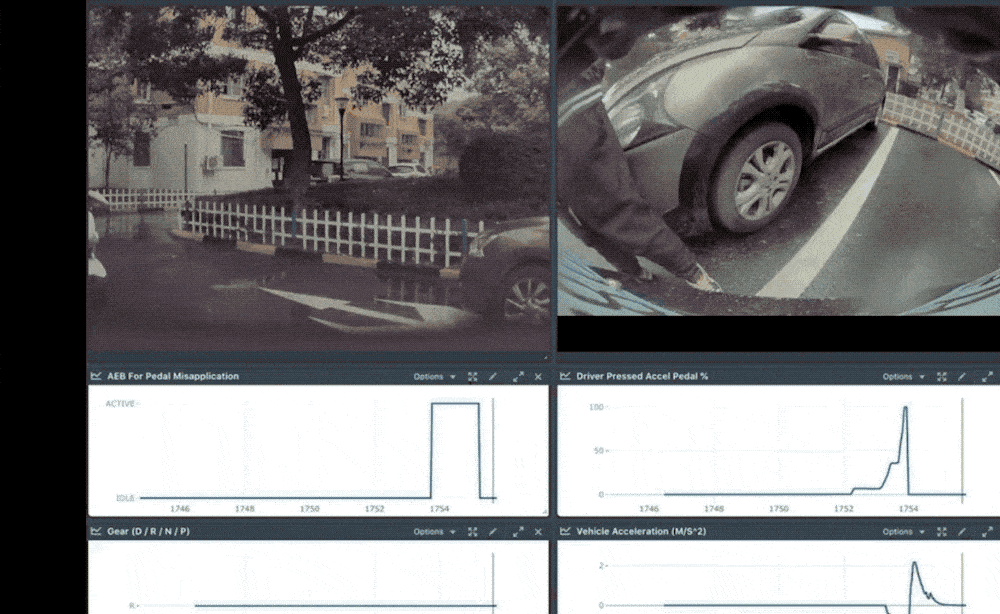
Collision refers to a crash caused by the driver accidentally pressing the accelerator pedal as the brake pedal. Ashok said that when the driver accidentally stepped on the accelerator as the brake, the car would accelerate and cause a collision. However, Tesla would recognize and automatically stop the acceleration, and automatically brake to prevent the collision.

Tesla AP starts to prevent the car from falling into the river
Automatically plan paths through occupancy rate vehicles
But getting the car to brake and stop smoothly can take seconds or minutes. Also, the car may not have enough time to recognize obstacles and make calculations while it's moving. Thus, Tesla uses neural networks for this purpose; especially with the more complex latent scenarios that have emerged recently. All the Tesla Autopilot team has to do is get space occupancy from the previous network.
First, the space occupancy is encoded into a super-compressed multilayer perceptron (MLP). Essentially, this MLP is an implicit representation of whether collisions can be avoided at any particular query state, and this collision avoidance method provides some guarantees within a certain time frame. For example, collisions can be avoided for 2 seconds or 4 seconds or some time frame.
Conclusion: Tesla continues to explore autonomous driving
Since Tesla brought the autopilot technology to the forefront, a large number of followers have emerged on the autopilot track. But Tesla has always been at the forefront of the industry, constantly exploring new methods of autonomous driving. This time, the person in charge of the Tesla Autopilot project brought a new technical interpretation. To a certain extent, it also shows us the highlights of Tesla's future self-driving technology in advance. With Tesla's spirit of continuous exploration, its autonomous driving will continue to lead the entire auto market.
Popular News



Latest News
Loading

