
In the realm of AI, Google has once again made a significant leap with the introduction of its latest innovation – the VLOGGER AI. This groundbreaking technology, part of Google’s new Gemini model, is set to revolutionize the way we interact with avatars and multimedia content. Google recently published a blog post on its GitHub page, introducing the VLOGGER AI model. Users only need to enter a portrait photo and audio content. The model can make these characters “move” and have facial expressions. The image can also read the audio content aloud.

Genesis of VLOGGER AI
Google’s VLOGGER AI is a pioneering creation that allows users to transform a still image into a lifelike, controllable avatar. This innovative model is built on the diffusion architecture, known for its prowess in text-to-image, video, and 3D modelling. By incorporating additional control mechanisms, VLOGGER takes the concept of avatar creation to new heights.
Understanding the Functionality of VLOGGER
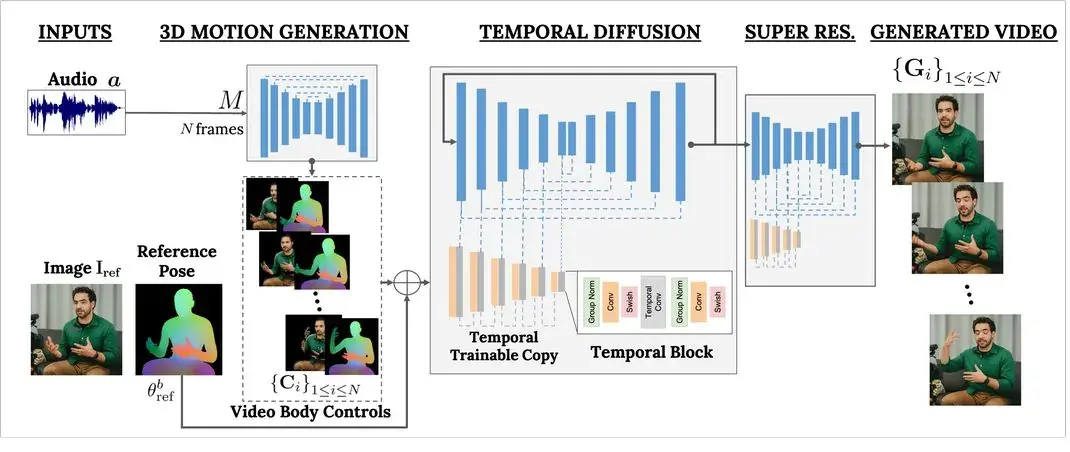
At its core, VLOGGER operates by processing an audio file and a still image through a series of intricate steps. It employs a 3D motion generation process followed by a “temporal diffusion” model to determine timings and movements. The model then refines the output, upscaling it to create a final, realistic avatar. By predicting motion for facial expressions, body gestures, and more, VLOGGER brings avatars to life with remarkable accuracy.
VLOGGER AI is a multi-modal Diffusion model suitable for virtual portraits. It is trained using the MENTOR database, which contains more than 800,000 portraits and more than 2,200 hours of videos. This allows VLOGGER to generate images of different races and ages. It can also generate portrait videos in different clothes and postures. The company said
“Compared with previous multi-modal models, the advantage of VLOGGER is that it does not need to be trained on each person, does not rely on face detection and cropping, and can generate complete images (not just faces or lips), and takes into account a wide range of scenarios (such as visible torsos or different subject identities) that are crucial for the correct synthesis of communicative humans”.
Unveiling the Limitations of VLOGGER
While VLOGGER represents a remarkable advancement in AI technology, it is essential to acknowledge its limitations. As a research preview, VLOGGER may not always perfectly replicate the natural movements of individuals. The model, although sophisticated, can encounter challenges with large motions, diverse environments, and handling longer videos. These limitations highlight the ongoing evolution and refinement required in the field of AI.
Exploring the Use Cases of VLOGGER
Google’s researchers envision a myriad of applications for VLOGGER AI. One of the primary use cases identified is its potential to revolutionize communication platforms like Teams or Slack. By enabling users to create animated avatars from still images, VLOGGER opens up new avenues for personalized and engaging interactions in virtual spaces.
Google sees VLOGGER as a step toward a “universal chatbot,” where AI can naturally interact with humans through voice, gestures, and eye contact.
The application scenarios of VLOGGER also include reporting, educational fields and narration. It can also edit existing videos. If you are not satisfied with the expressions in the video, you can make adjustments.
Conclusion: Paving the Way for AI-Driven Innovation
In conclusion, Google’s launch of the multi-modal VLOGGER AI within the Gemini model represents a significant stride in AI technology. This innovation sets the stage for a new era of AI-driven experiences, from creating lifelike avatars to advancing language understanding and visual reasoning. As Google continues to push the boundaries of AI capabilities, the future holds immense promise for transformative applications across various domains.



