
Artificial Intelligence is a very important tool that helps users simplify tasks. However, training Google AI to understand complex usage scenarios is not an easy task. This is more difficult when dealing with statements that have emotions in them. Let us give two of such sentences that have emotions in them: “I really thank you for all you’ve done.” “Listen to me, thank you, because of you, things are much easier now…”

Maybe you will say, this is very simple, isn’t it a stalk that has been played frequently recently? However, it is not an entirely simple process considering that there are different people with different needs. However, there is a generation gap with popular culture, not only for the elders but also for AI. Thus, what AI needs to learn for elders is much different from what it needs to learn for young people. A recent article found that the error rate with Google AI is as high as 30%.

Google AI misinterprets some phrases
Here are some examples of sentences that Google AI easily misinterpret
“Aggressively tell a friend I love them”
Google misinterpret this phrase as “ANGER” and this completely changes the intent
“You almost blew my fucking mind there”
Google AI also misinterpret this phrase as “ANNOYANCE” which also changes the meaning.
From these, we can see that Google AI in some cases simply takes the statement out of context. Artificial intelligence becomes artificial mental retardation in seconds. How did it make such an outrageous mistake?
How does it make the mistake?
This has to start with the way he judges. When the Google data set labels comments, it is judged by picking out the text alone. We can take a look at the image below, the Google dataset all misjudges the emotion in the text as anger.
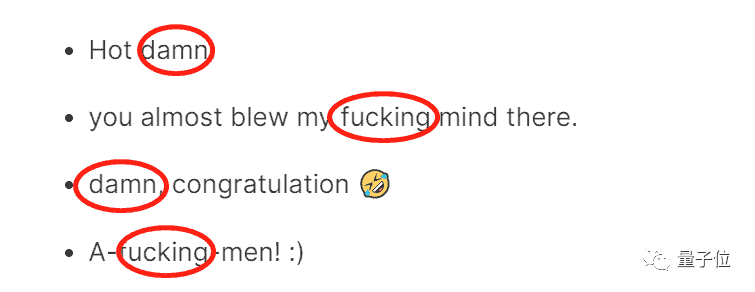
Why don’t we speculate on the reason why the Google data set is wrong. Take the above example, there are some “swear words” in these four comments.
The Google data set uses these “swear words” as the basis for judgment. However, if you read the entire review carefully, you will find that this “basis” is only an emphasis of the entire sentence. Thus, this makes no practical meaning.
Most of the comments by users often do not exist in isolation. Also, factors such as the posts they follow and the platforms they publish on may cause the entire semantics to change.
For example, just look at this comment:
Gizchina News of the week
“his traps hide the fucking sun”
It’s hard to judge the emotional element of this alone. But maybe it’s not hard to guess if it’s a comment from a muscle site (he just wanted to compliment the guy’s muscles).
It is unreasonable to ignore the post to which the comment is directed. In fact, to single out a word with a strong emotional attachment to judging its emotional element might be wrong. A sentence does not exist in isolation, it has its specific context. This means that its meaning changes with the context.
Putting comments into a complete context to judge their emotional attachment may greatly improve the accuracy of judgment. But the high error rate of 30% is not just “out of context”, there are deeper reasons.
Google AI has a lot to learn
In addition to context interfering with dataset discrimination, the cultural background is also a very important factor. As large as a country or region, or as small as a website community, there will be its own internal cultural symbols. These symbols will be difficult for people outside the circle of cultural symbols to interpret. This creates a difficult problem: if you want to more accurate judgement. To understand the sentiment of community comments, it is necessary to conduct some data training on the community to gain a deep understanding of the cultural genes of the entire community.
On Reddit, comments from netizens pointed out that “all raters are native English-speaking Indians”.
This leads to misunderstandings of some very common idioms, modal particles and some specific “stalks”. Having said so much, the reason for such a high rate of error in data set discrimination is obvious. But at the same time, there is also a clear direction for improving the accuracy of AI’s ability to identify emotions. Below are some suggestions
Suggestions to improve AI capacity
First, when labelling comments, you need to have a solid understanding of the cultural context in which they live. Taking Reddit as an example, to judge the emotional attachment of its comments, it is necessary to have a thorough understanding of some American culture and politics and to be able to quickly get the “stalk” of the exclusive website.
Secondly, it is necessary to test whether the label’s judgment of some sarcasm, idioms, and memes is correct to ensure that the model can fully understand the meaning of the text
Finally, check the model judgment against our real judgment to give feedback to better train the model.
One More Thing
AI Daniel Wu Enda once launched a data-centric artificial intelligence movement.
Shift the focus of AI practitioners from model/algorithm development to the quality of the data they use to train models. Wu Enda once said:
Data is the food of artificial intelligence.
The quality of the data used to train it is also critical for a model, and in emerging data-centric approaches to AI, data consistency is critical. In order to get correct results, the model or code needs to be fixed and data quality improved iteratively.


